采集规则示例
有些文章内容太长会采用分页模式来显示
首先我们在“采集器设置»获取内容»内容页分页”中开启分页,文章一般都是正文有分页,我们将“正文”字段添加为“分页内容字段”
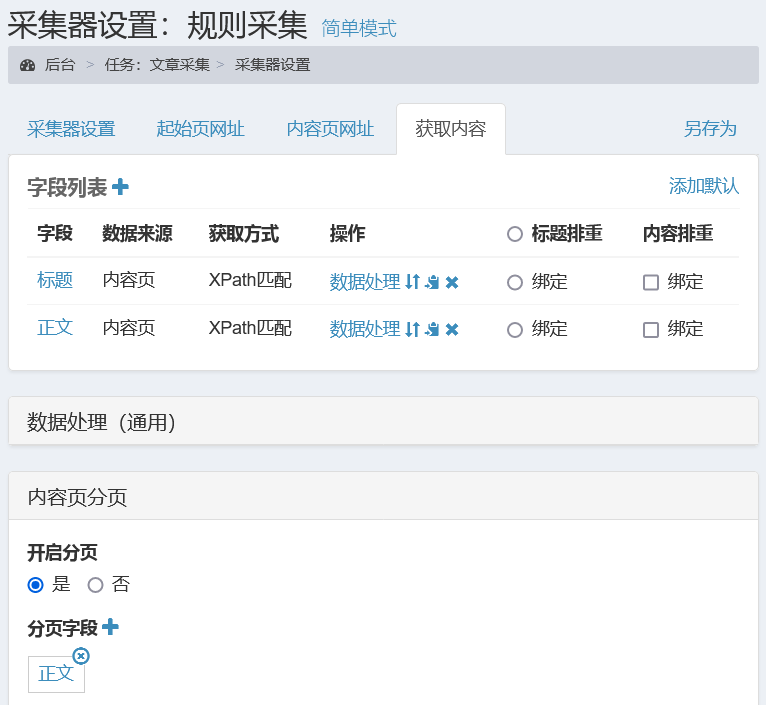
以文章 http://shili.skycaiji.com/article/news/pg/id/124.html 为例,文章页面图片:
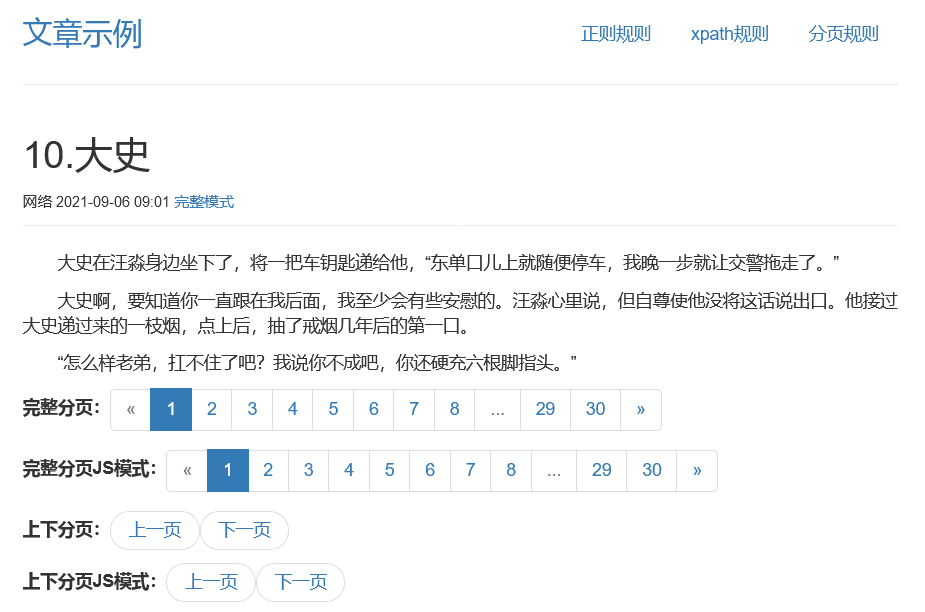
图中我们可以看到有4种分页形式:完整分页、上下分页、完整分页JS模式和上下分页JS模式
分页连接的格式为:article/news/pg/id/数字.html?page=数字
通过“测试»分析网页”功能获取到各个分页区域的xpath:
- 完整分页://*[@id="page_list"]/li[1]
- 上下分页://*[@id="page_list"]/li[3]
- 完整分页JS模式://*[@id="page_list"]/li[2]
- 上下分页JS模式://*[@id="page_list"]/li[4]
以上xpath值可以在“内容页分页»获取分页区域”中设置以获取固定区域的分页链接,否则将获取整个页面的分页链接
分页链接规则:
完整分页和上下分页直接通过a标签获取链接即可:<a href="[内容1]">
JS模式分页通过查看源码发现链接格式为:<a onclick="javascript:page('网址');">
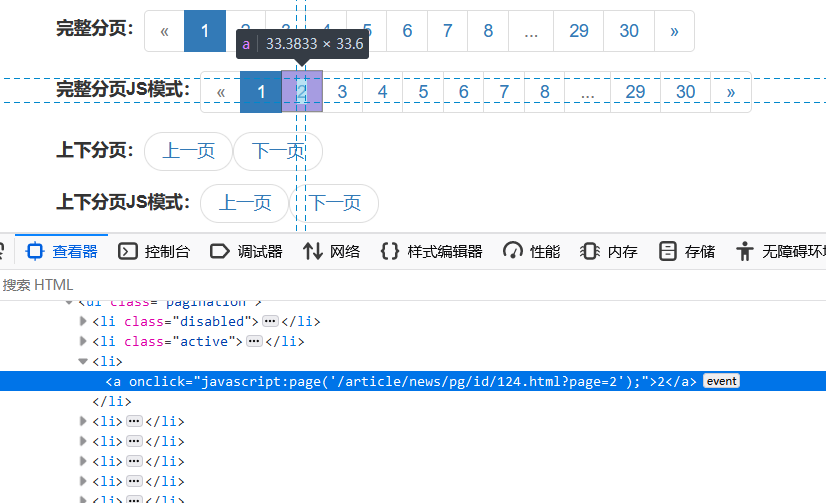
使用规则匹配出分页链接:<a onclick="javascript:page\('[内容1]'\);">
因为JS模式不能自动补全网址,所以要在“拼接成最终分页链接”中填写:http://shili.skycaiji.com[内容1]
为了防止匹配到非分页链接,在“内容页分页»分页网址过滤»必须包含”中填写“page=”,精准一些则用“article/news/pg/id/\d+\.html\?page=\d+”
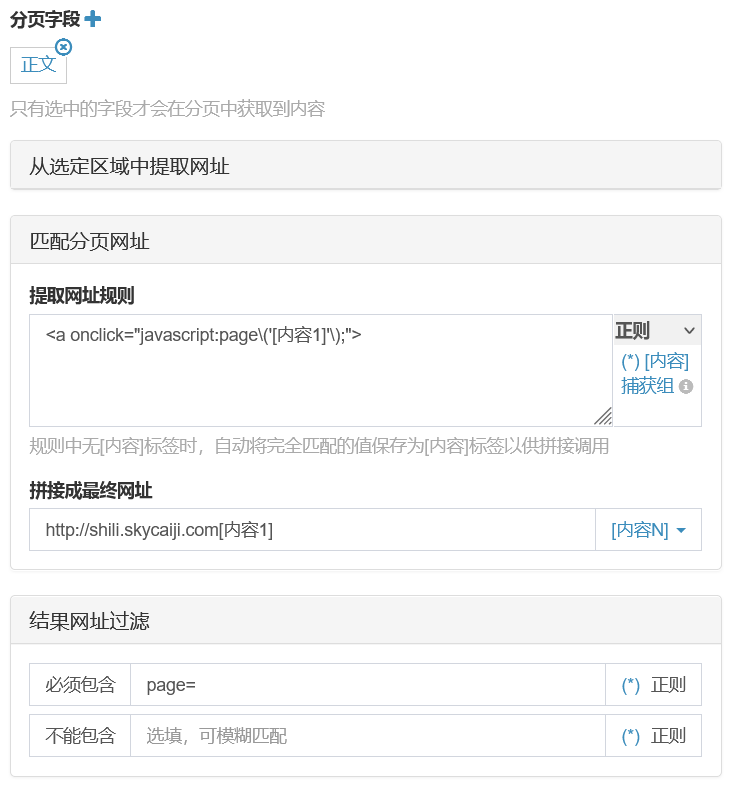
我们测试下“完整分页JS模式”的链接抓取,“测试»抓取分页”效果
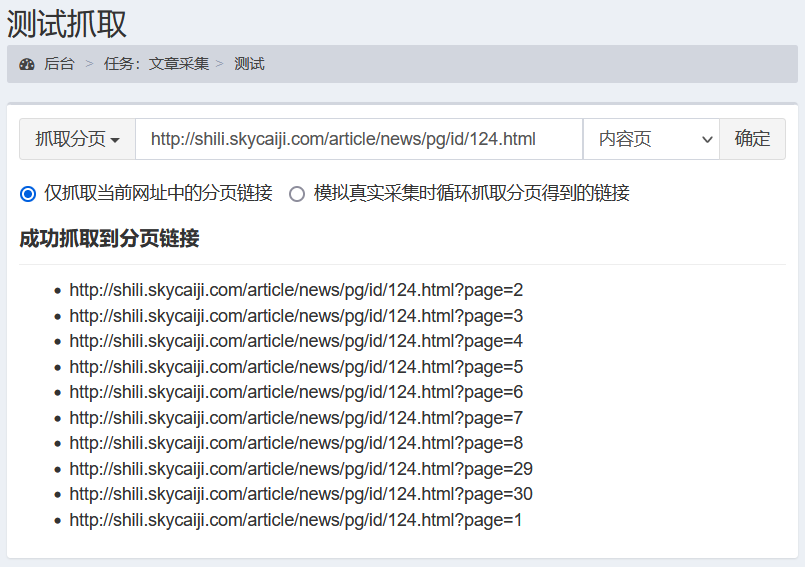
注意:很多网站由于程序问题会出现2种格式的文章首页链接,比如示例中的文章首页链接为:http://shili.skycaiji.com/article/news/pg/id/124.html和http://shili.skycaiji.com/article/news/pg/id/124.html?page=1(从第二页开始文章首页为该链接),这2个链接内容是一样的会导致文章首页重复抓取
解决方法:在“内容页分页»分页网址过滤»不能包含”中填写page=1$即排除掉第一页链接
常见问题:
- 上下页模式每次只能抓取一个分页链接能采集完整吗?可以的,程序会根据下一页自动抓取到最后一页,可以用“测试»抓取字段”看看数据是否抓取完整
- 如果分页链接顺序打乱了,文章分页内容会乱吗?不会的,程序自动根据分页编号排序,会按照正常分页顺序采集内容
- 最大分页数是怎么回事?是为了防止出现死循环,当实际分页数不超过最大分页数时使用实际分页数,超过最大分页数时使用最大分页数
本示例已上传至云平台http://www.skycaiji.com/rule/100113