字段
规则匹配
添加、编辑字段时使用规则匹配可精准获取目标页面的数据
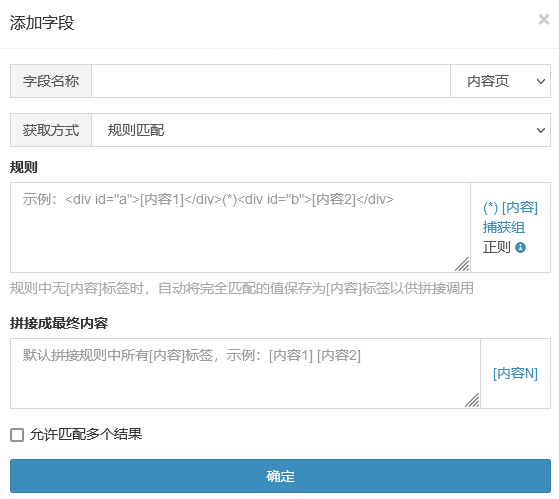
“规则”支持:(*)(通配符)、正则表达式,使用[内容](通用匹配)或捕获组(正则捕获组)将匹配的数据保存为标签,在“拼接内容”中引用[内容N]标签组成结果
[内容]和捕获组的区别:[内容]会自动转换成固定格式捕获组:(?<nr>.*?)
而捕获组:(?<nr>[\s\S]*?),可以编写任意正则表达式
[内容]适用于精准度不高的通用匹配,捕获组适用于精准匹配
默认为单个匹配,多个匹配可勾选“允许匹配多个元素”
示例
以新闻为例,页面中有许多元素,而我们只需要标题和正文
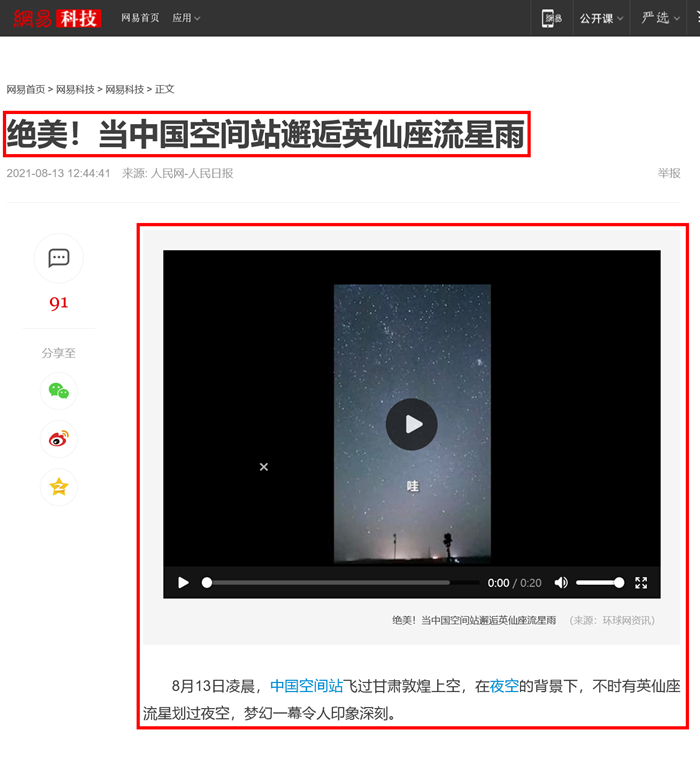
鼠标右键,查看页面源代码,使用键盘 CTRL+F 搜索标题,找到标题的位置

即标题的规则为:<h1 class="post_title">[内容]</h1>
同理,找出正文所在位置

正文处于标记的红框html代码之间
即正文的规则为:<div class="post_body">[内容]</div>\s+<!-- 相关 -->
常见问题:
- 匹配到多余的内容:规则要确保匹配的唯一性防止出现贪婪匹配,可以优先选择有id属性的标签!
- 匹配到的内容在页面中显示会导致版面错乱:规则没有包含结束元素或包含了其他块的开始元素导致匹配的内容形成不了html闭合
规则匹配需要一些正则技术且编写时需仔细反复推敲,一个小细节就可能导致匹配错误或匹配的结果不同
如您不熟悉正则或觉得正则比较繁琐,可以使用XPATH匹配(简单易上手,匹配的结果精准度高)
XPATH匹配
添加、编辑字段时使用XPath匹配可方便快捷获取目标页面的数据
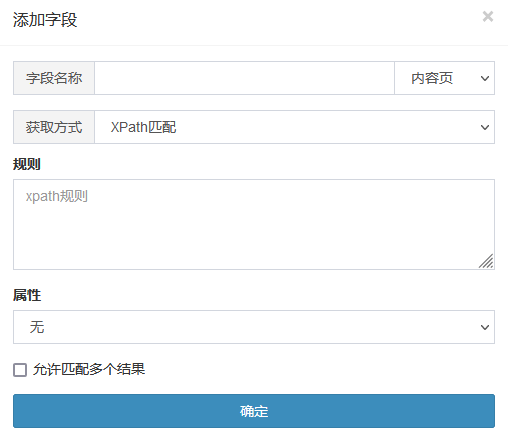
“规则”处填写xpath代码,默认匹配一个节点
几个常用的节点属性:
- innerHtml:节点内的HTML代码
- outerHtml:包括节点本身的HTML代码
- text:节点包含的文本内容
- value:节点的值
一般情况下使用innerHtml
示例
以新闻为例,页面中有许多元素,而我们只需要标题和正文
鼠标悬停在标题上,右键点击检查(无此功能可使用谷歌浏览器)
控制台中会自动跳到相应的html代码,右键代码»Copy»Copy XPath 即可
标题的XPath规则为://*[@id="container"]/div[1]/h1
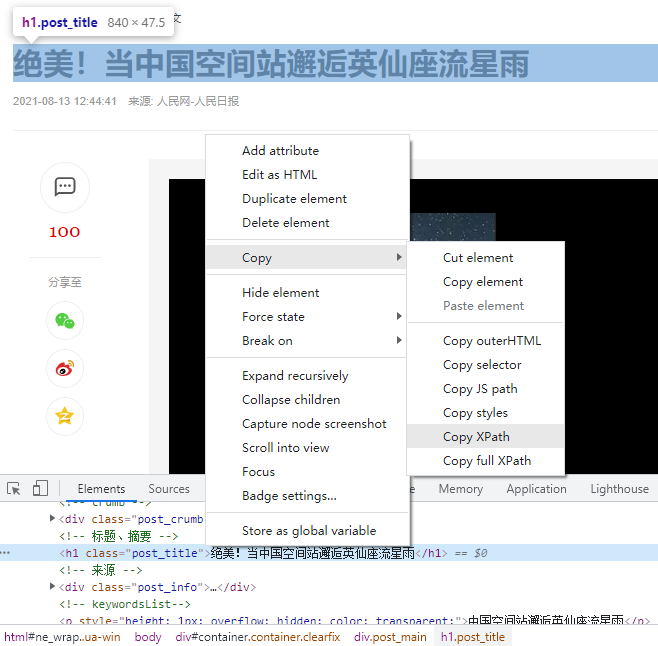
同理,鼠标悬停在正文中,右键点击审查元素
在控制台底部选择节点,当正文被阴影覆盖时表示为正文节点,右键节点代码»Copy»Copy XPath
正文的XPath规则为://*[@id="content"]/div[2]
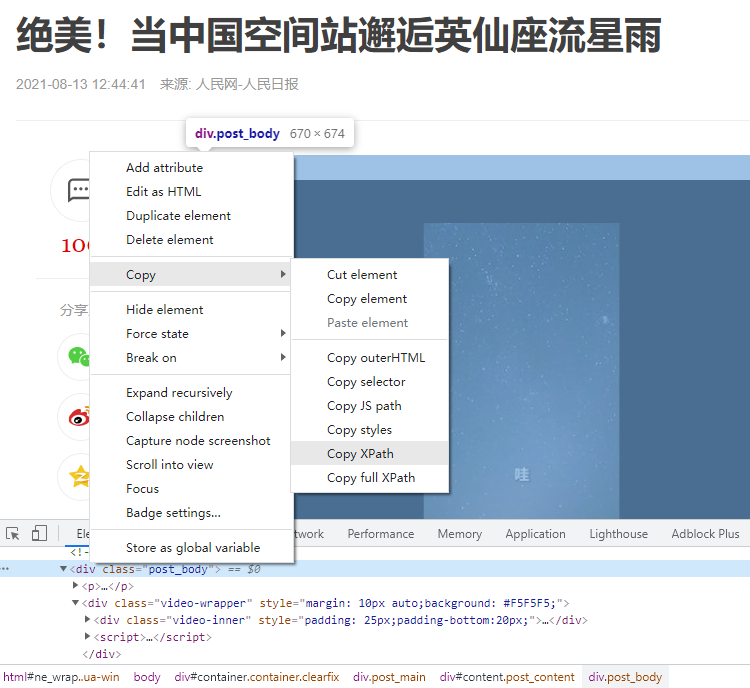
xpath简单易上手且准确度高,推荐使用!
新手推荐使用简单模式
在任务采集器设置的标题中点击进入“简单模式”即可直接分析网页,只需点选就能获取到元素的xpath值,省去繁琐的分析步骤!
JSON提取
如果目标不是html格式而是json数组,规则处直接输入键名,子元素用:a.b.c,通配符*可获取同级别节点的所有数据
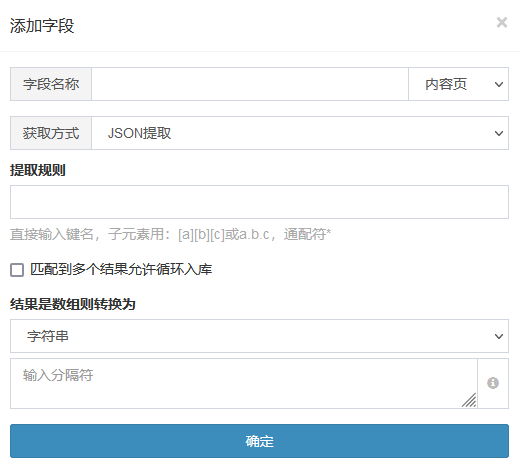
使用“采集器后台»工具»json解析”可将json字符串解析为可视化的树形结构
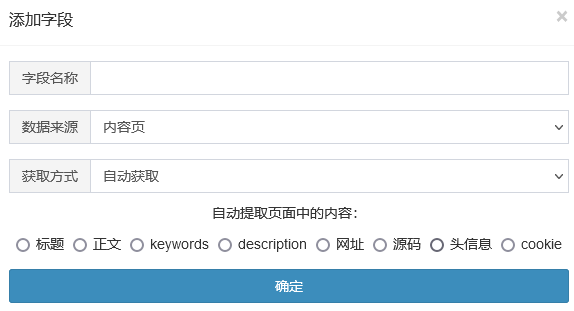
自动获取
可智能识别标题、正文、keywords、description、网址、源码、头信息、cookie等,注意:正文不能保证100%识别,如需精准请使用规则和xpath
[内容]标签
可调用内容页、多级页、关联页中区域规则或网址规则里的[内容]标签
数据生成
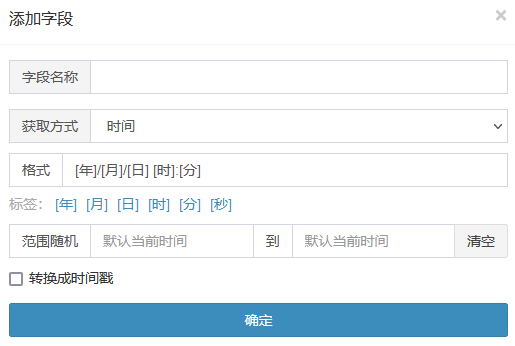
可选择固定文字、随机数字、时间、随机抽取
时间可设置格式、随机范围,勾选“转换成时间戳”获取数字形式的时间
字段提取内容
从某个字段的内容中提取数据
字段组合
将多个字段组合拼接成新的内容